
We continue now our journey through neural networks by diving straight into one of the most known frameworks for python, this is PyTorch.
In my first post, I create a Neural Network from scratch just using Numpy. I try different architectures of networks, tuning different hyperparameters. The last example I test it on is the Mnist dataset consisting of handwritten numbers from 0 to 9. The data is presented in images of shape [28,28,1]. The network used has 2 convolution layers, followed by a layer to flatten it, and finally 2 fully connected layers.

In this post, we will continue where we left it, by creating once again a very similar network but this time using Pytorch. We will then move on to improving the network by adding additional layers, using max-pooling. We will also do dropout regularization to tackle the problem of overfitting.
Let’s get started!
Same network in Pytorch
I will be using torch 1.13.7 (and Cuda 11.7 for those that want to train with GPU). Check out how to install PyTorch here.
We start by loading our dataset from PyTorch, and some of the in-built very convenient functions like normalize.
# Load,and set train and test data
# Normalize the dataset
train_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST(
"/files/",
train=True,
download=True,
transform=torchvision.transforms.Compose(
[
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((dataset_mean,), (dataset_std,)),
]
),
),
batch_size=batch_size,
shuffle=True,
num_workers=2,
)
We built the CNN with the same architecture as our previous post. And here we can appreciate how much simpler it is to, as it already has all the activation functions inbuilt. I will also leave comments on the dimensions of the incoming Mnist tensor, to make it easier to follow what is happening through the network.
class NeuralNetwork(nn.Module):
def __init__(self) -> None:
super(NeuralNetwork, self).__init__()
# Default padding=0 and stride =1
self.conv1 = nn.Conv2d(1, 1, kernel_size=3)
self.conv2 = nn.Conv2d(1, 1, kernel_size=3)
self.fc1 = nn.Linear(24 * 24, 100)
self.fc2 = nn.Linear(100, 10)
def forward(self, x):
# input shape: [64, 1, 28, 28]
# output shape: [64, 1, 26, 26]
x = F.relu((self.conv1(x)))
# input shape: [64, 1, 26, 26]
# output shape: [64, 1, 24, 24]
x = F.relu(self.conv2(x))
# flatten input shape: [64, 1, 24, 24]
# output shape: [64, 24*24]
x = x.view(-1, 24 * 24 * 1)
# input shape: [64, 24*24]
# output shape: [64, 100]
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
# input shape: [64, 100]
# output shape: [64, 10]
x = self.fc2(x)
softmax = F.log_softmax(x, 1)
return softmax
To analyze the results, we run 100 epochs, and we test it against the whole test dataset. For evaluation, as a log function, we use the negative log-likelihood. We achieve the following accuracy.
Test set: Avg. loss: 0.10831, Accuracy: 9674/10000 (96.74%)
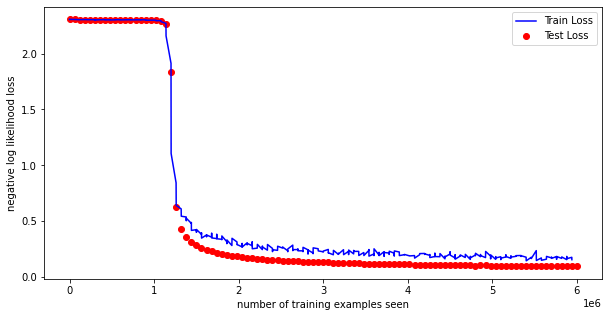
As shown in the previous post, the results are quite impressive for such a simple network. Of course, it would be very interesting to train such a simple network in a more complex dataset and see how it behaves then (and maybe this will be done in the next posts).
But let’s test our model in some samples and see what results we get. As we can see for the 6 random samples selected our model was able to predict the correct label.

Ok, so clearly using PyTorch has simplified greatly our efforts in creating this simple CNN. However, a big risk I see in using this type of framework is that we create a large level of abstraction between what we code and the math happening behind it, sometimes making it hard to understand what type of algorithms or calculations are happening in the back. I believe coding a network from scratch at least once, is a very good exercise for any machine learning practitioner. This will support the needed fundamental knowledge for more advanced networks.
With this said, let us try to improve our network further so that in future posts we can tackle more complex problems.
Improve the network
ReLU (Rectified Linear Unit)
Something I have not mentioned but if you have checked the above code, you might have noticed, is that for my Pytorch implementation, I have used ReLU as my activation function. Among other reasons, why I have used ReLu is to speed up training, but also because it is a widespread activation function that has proven to give very good results in CNNs. (If you want to check out the basic implementation of ReLU without Pytorch, I also have it coded in my from_scratch GitHub repo).
f(x) = max(0, x)ReLU also helps solve the issue of vanishing gradient. I will not deep dive into it, but recommend reading this post for a better understanding.
Batch Size
Memory allocation during training is a problem that we will encounter when we load larger datasets. Building up batches from your Dataset helps solve this problem. For example for our model we select a batch size of 64, this means that we will divide the whole training sets compromising 60000 images, into batches of 64 images (a total of 938 batches), and only load one of these batches at a time, saving a lot of memory use. We will then also use a minibatch gradient descent algorithm to deal with the fact that we have divided our dataset into batches.
Dropout
Dropout is a type of regularization.
Regularization is a technique that aims to solve the problem of overfitting, which can happen when networks can´t generalize and fit too closely the training set, but performs poorly on new data. For our basic network, we will use Dropout, which consists of randomly dropping nodes, creating noise, which helps solve the problem of overfitting.
By dropping a unit out, we mean temporarily removing it from the network, along with all its incoming and outgoing connections
Dropout: A Simple Way to Prevent Neural Networks from Overfitting, 2014.
For a deeper dive checkout this great post at:
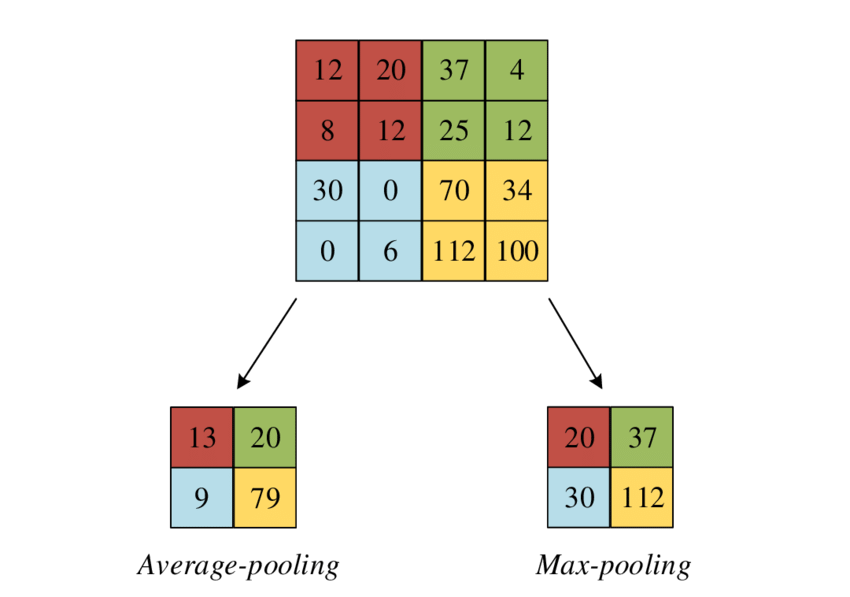
Pooling
Pooling is a layer added to a neural network (typically after a convolution layer) to generate a down-sampled feature map of the one detected on the input. This will reduce the number of parameters and thus the computational complexity of the network.
Typical pooling methods are max pooling and average pooling.
Implement the network
So now that we have different new concepts that we want to test out. Let’s see how easy it is to implement in Pytorch.
class NeuralNetwork(nn.Module):
def __init__(self) -> None:
super(NeuralNetwork, self).__init__()
# Default padding=0 and stride =1
self.conv1 = nn.Conv2d(1, 20, kernel_size=5)
self.conv2 = nn.Conv2d(20, 30, kernel_size=5)
self.conv2_dropout = nn.Dropout2d()
self.fc1 = nn.Linear(480, 60)
self.fc2 = nn.Linear(60, 10)
def forward(self, x):
# input shape: [64, 1, 28, 28]
# output shape: [64, 10, 24, 24]
x = F.relu(F.max_pool2d(self.conv1(x), 2))
# input shape: [64, 10, 12, 12] (stride for pooling counts as kernel size)
# output shape: [64, 20, 8, 8]
x = F.relu(F.max_pool2d(self.conv2_dropout(self.conv2(x)), 2))
# flatten input shape: [64, 20, 4, 4]
# output shape: [64, 320]
x = x.view(-1, 480)
# input shape: [64, 320]
# output shape: [64, 50]
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
# input shape: [64, 50]
# output shape: [64, 10]
x = self.fc2(x)
softmax = F.log_softmax(x, 1)
return softmax
All of these functions are ready to use with less than a line of code.
We have increased the accuracy to more than 99%!
Train Epoch: 100 [59520/60000 (99.15%)] Loss: 0.09361
Test set: Avg. loss: 0.02367, Accuracy: 9937/10000 (99.37%)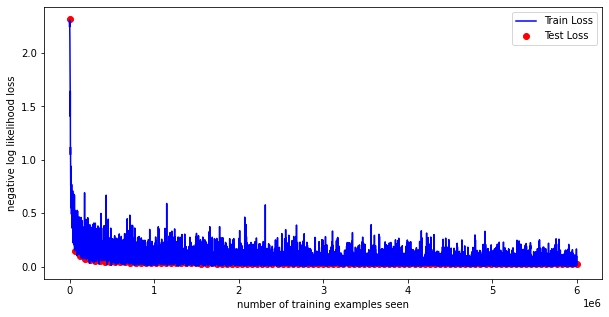
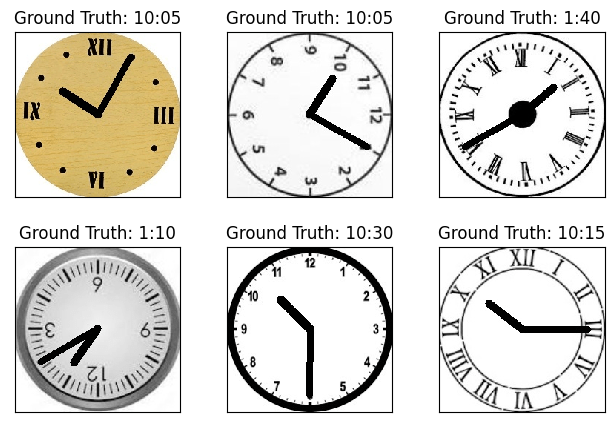
Finally lets check the results on some samples

Well, we can clearly see that there are many advantages to using frameworks instead of coding from Scratch. These open-source frameworks are also supported by many data scientists and machine learning practitioners around the world, so it is the place to look for the state-of-the-art.
In future posts, we will take a look at more complex datasets, and perform different tasks, in the area of computer vision but I would also like to explore natural language processing or Deep learning in other types of data. I am also interested in doing the same exercise as this post but in TensorFlow, to show that they are very similar.
Check out all my code in my GitHub.
References
Cross Entropy
https://vitalflux.com/cross-entropy-loss-explained-with-python-examples/
http://www.adeveloperdiary.com/data-science/deep-learning/neural-network-with-softmax-in-python/
Pytorch
https://www.datacamp.com/tutorial/pytorch-tutorial-building-a-simple-neural-network-from-scratch
Vanishing Gradient
https://towardsdatascience.com/the-vanishing-gradient-problem-69bf08b15484
Regularization
https://machinelearningmastery.com/dropout-for-regularizing-deep-neural-networks/
Pooling
https://machinelearningmastery.com/pooling-layers-for-convolutional-neural-networks/



Leave a comment